

Với các nhà thiết lập và quản trị website, các thuật ngữ như crawl, web spiders,… chắc không còn xa lạ. Nhưng với người mới bắt đầu, thì định nghĩa Crawl là gì khá là mong lung. Bài viết này, sẽ giới thiệu tới bạn nguyên lí hoạt động của web crawlers? Mối liên hệ giữa crawler và SEO? Tại sao công cụ cũng có tên Spiders? Và rất nhiều thông tin về công cụ tiện tích này!
1. Định nghĩa về Crawl
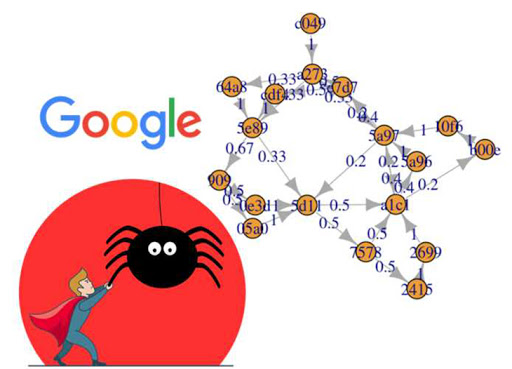
Với giới Marketing cũng như người làm SEO, crawl là thuật ngữ chuyên dụng phổ biến. Nghĩa của crawl data là “cào” dữ liệu, nói cách khác là thu thập và phân tích thông tin. Google, Bing Yahoo… là các nền tảng thường xuyên sử dụng công cụ này. Sau khi có dữ liệu, công cụ sẽ tiến hành đọc mã nguồn HTML. Rồi lọc thông tin theo yêu cầu của Search Engine hoặc người truy cập. Bạn có thể chọn bất cứ trang nào để đọc và phân tích thông tin.
2. Vậy web crawler là gì?
Có nhiều cái tên để nói về công cụ thu thập thông tin: crawl, web drawler, spider, bot công cụ tìm kiếm,… Chúng có nhiệm vụ chung là tải về và index nội dung bất kì đâu trên mạng.
Bản thân thuật ngữ crawl mang tính chất diễn tả qui trình tự động vào trang web để thu thập thông tin, thông qua phần mềm. Tìm hiểu các page trong website, truy xuất dữ liệu lúc cần là mục tiêu của bot. Các công cụ tìm kiếm là cơ quan vận hành các bot.
Khi người dùng thực hiện tìm kiếm, thuật toán sẽ được tiến hành trên thông tin mà web crawler thu thập được. Từ đó công cụ tìm kiếm sẽ cung cấp đường dẫn liên kết phù hợp với yêu cầu của người dùng. Từ khóa được người dùng nhập tại Google hoặc Bing. Sẽ sắp xếp thành danh sách website trên kết quả tìm kiếm.
3. Làm sao để không bỏ sót thông tin?
Vì lượng thông tin dồi dào trên mạng, gây trở ngại cho người đọc trong việc nhận biết thông tin nào đã được index đúng cách. Nắm bắt điều đó, để không bỏ sót thông tin cần cung cấp. Bot sẽ ưu tiên thực hiện nhiệm vụ với website phổ biến. Từ siêu liên kết trên website phổ biến, thực hiện tiếp nhiệm vụ trên các trang phụ. Trên thực tế, ước tính 40 đến 70% là lượng website có index ở mục tìm kiếm đúng cách từ bot trên công cụ tìm kiếm thu thập thông tin.
4. Cách hoạt động của crawl website

Một lần nữa vì lượng website quá “khủng” trên Internet, để hệ thống công việc dễ hơn web crawlers sẽ bắt đầu bởi list những URL biết trước. Thu thập thông tin webpage ở các URL là bước đầu tiên. Sau khi có được các trang, web crawlers tiếp tục thu thập siêu liên kết đến những URL khác. Liên kết mới tìm sẽ được thêm vào list những page thu thập dữ liệu kế tiếp.
Để tiết kiệm thời gian tìm kiếm và phân tích quá nhiều website, web crawlers có các chính sách nhất định. Công cụ sẽ chọn lọc được nên thu thập thông tin website nào, có trình tự thu thập riêng. Mức độ thu thập dữ liệu lại để cập nhập nội dung phù hợp.
Một số “chuẩn” mà web crawler đặt ra để sàng lọc trang thu thập thông tin:
- Số lượng trang phụ liên kết đến page chính
- Lưu lượng truy cập đến trang từ người dùng
- Các yếu tố chứng minh khả năng truyền tải dữ liệu thiết yếu của trang.
Ba yếu tố trên biểu thị chất lượng, uy tín, thẩm quyền của website để thuyết phục web crawlers chọn và index.
Revisiting webpages:
Về quá trình truy cập lại định kì các website từ web crawlers. Mục đích là để index nội dung mới khi các website có cập nhật, điều chỉnh, di chuyển vị trí.
5. Nguồn gốc tên Spiders của Crawlers
Tên gọi spiders của các web crawlers bắt nguồn từ World Wide Web “www” – mạng lưới URL của đa số website. Dựa theo đó, như những “chú nhện” siêng năng làm việc trên “mạng nhện/ lưới nhện”. Tên spiders ra đời để chỉ nhiệm vụ thu thập và phân tích thông tin trang web của web crawlers.
6. SEO chịu tác động gì bởi web crawler?

Nói về mối liên hệ giữa crawl và SEO, SEO là một trong yếu tố giúp chuẩn bị tốt content. Để trang được index cũng như hiển thị trên trang kết quả tìm kiếm. Nội dung chưa hoàn chỉnh, spider bot chưa thể thu nhập thông tin của trang đó. Nên quá tình trang được index và hiển thị trên kết quả tìm kiếm cũng bị trì hoãn theo. Chặn bot crawlers làm nhiệm vụ, nghĩa là bạn vô tình hạn chế nguồn lưu lượng truy cập miễn phí của mình trên trang tìm kiếm.
7. Một số bot crawler phổ biến hiện nay
Ngày nay người dùng sẽ biết đến những loại bot crawler phổ biến như sau:
- Google: gồm hai loại Googlebot tìm kiếm, dành cho máy tính và loại dành cho điện thoại. Gọi là Googlebot desktop và Googlebot Mobile.
- Bing: Hay còn gọi là Bingbot
- Yandex: Phổ biến ở Nga, gọi là công cụ tìm kiếm Yandex Bot
- Baidu: Thông dụng ở Trung Quốc, có tên là công cụ tìm kiếm Baidu Spider.
8. Tầm quan trọng của phân loại bot
Không phải bất cứ bot nào cũng có lợi cho website, ở đây phân chia thành 2 loại: Bot độc hại và bot an toàn
- Loại độc hại: Bạn sẽ không lường trước được những sự cố mà loại bot này có thể gây ra. Từ trải nghiệm người dùng, máy chủ, an ninh dữ liệu,… đều có thể là mục tiêu tấn công của bot độc hại.
- Bot an toàn: Ra đời để “tiêu diệt”, hạn chế tối đa các bot độc hại. Là lí do web crawlers xuất hiện, “len lỏi” vào các tính năng website.






